GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
本文的idea是MHA和MQA两种方案的折衷,正如文章中的描述GQA-1就是MQA,GQA-H就是MHA。本实验中使用的是MQA-8,因为实验结果表明这是一种最优的选择。
abstract
多查询注意力(MQA)仅使用单个键值头,大大加快了解码器推理速度。然而,MQA 可能会导致质量下降,而且仅仅为了更快的推理而训练单独的模型可能并不可取。(1)提出了一种方法,使用 5% 的原始预训练计算将现有的多头语言模型检查点升级为 MQA 模型,并且(2)引入分组查询注意力(GQA),这是多查询注意力的泛化,它使用中间(多于一个,少于查询头的数量)数量的键值头。实验表明经过训练的 GQA 实现了接近多头注意力的质量,并且速度与 MQA 相当。
introduction
自回归解码器推理是 Transformer 模型的严重瓶颈,因为每个解码步骤加载解码器权重以及所有注意键和值都会产生内存带宽开销。通过多查询attention可以大幅减少加载键和值的内存带宽。然而,多查询注意力(MQA)可能会导致质量下降和训练不稳定,并且训练针对质量和推理进行优化的单独模型可能不可行。
这项工作包含两项对大型语言模型更快推理的贡献。
- 首先,我们表明具有多头注意力 (MHA) 的语言模型检查点可以进行上训练(uptrained),以使用 MQA 来使用原始训练计算的一小部分。这提供了一种经济高效的方法来获取快速多查询以及高质量的 MHA 检查点。
- 其次,我们提出分组查询注意力(GQA),这是多头和多查询注意力之间的插值,每个查询头子组具有单个键和值头。我们表明,经过训练的 GQA 实现了接近多头注意力的质量,同时几乎与多查询注意力一样快。
Method
Uptraining
从多头模型生成多查询模型分为两个步骤:首先,转换检查点,其次,进行额外的预训练,以使模型适应其新结构。图1展示了将多头检查点转换为多查询检查点的过程。键和值头的投影矩阵均值合并为单个投影矩阵,我们发现这比选择单个键和值头或从头开始随机初始化新的键和值头效果更好。
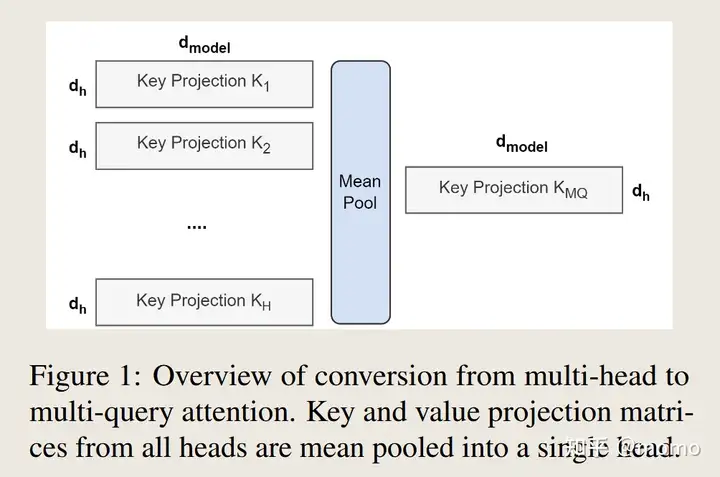
随后,转换后的检查点将按照原预训练方案,以α的小比例对其原始训练步数进行短期预训练。
Grouped-query attention
分组查询注意力将查询头分为 G 组,每个组共享一个键头和值头。 GQA-G是指G组的分组查询。 GQA-1 具有单个组,因此具有单个键和值头,相当于 MQA,而 GQA-H 具有等于头数的组,相当于 MHA。这里是使用对原始头进行均值池化来计算得到新的头。
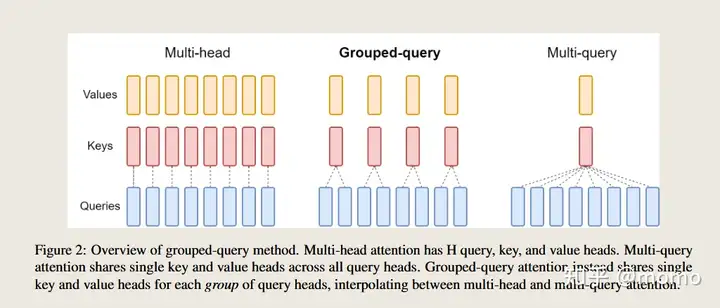
这是一种对MHA和MQA的权衡,因为将H个key和value减少为单个头,从而减少了key,value缓存的大小从而减少了H倍的需要加载的数据量。
此外,对于更大的模型,注意力机制带来的内存带宽开销相对较小。这是因为KV缓存的大小与模型的维度成线性增长,而模型的浮点运算次数和参数量却与模型维度的平方成正比。最后,对于大模型的标准分片方法,会根据模型分区的数量来复制每一个Key和Value头;而GQA消除了这种分片方式带来的浪费。
同时GQA不会应用与编码器的Transformer的self attention层中,因为编码器是并行计算的,内存带宽不是主要瓶颈。
Experiments
Experimental setup
-
Configurations 所有模型均基于 T5.1.1 架构,并使用 JAX、Flax和 Flaxformer1 实现。将 MQA 和 GQA 应用于解码器自注意力和交叉注意力,但不应用于编码器自注意力。
-
Uptraining 上训练的模型从公共 T5.1.1 检查点初始化。键和值头均值池化为适当的 MQA 或 GQA 结构,然后使用原始预训练设置和数据集对原始预训练步骤的进一步 α 比例进行预训练。
-
Data 对摘要数据集 CNN/Daily Mail等进行评估;翻译数据集 WMT 2014 英语-德语。没有对 GLUE等流行的分类基准进行评估,因为自回归推理不太适用于这些任务。
-
Fine-tuning 对所有任务使用 0.001 的恒定学习率、128 的批量大小和 0.1 的 dropout 率。 使用贪婪解码进行推理。
Main results
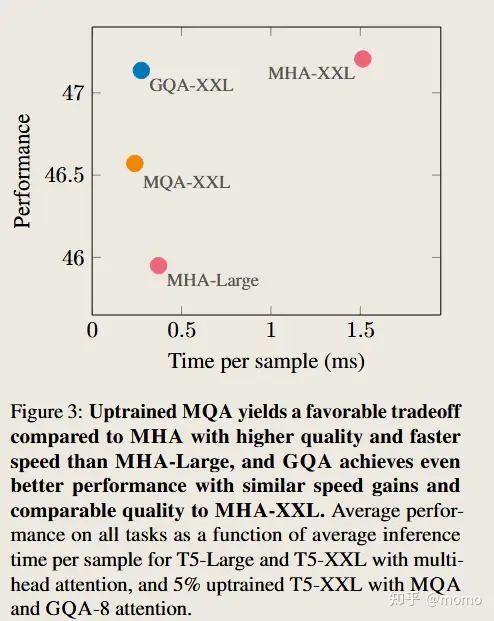
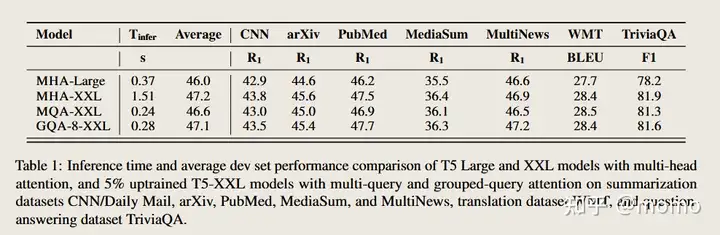
图 3 显示了 MHA T5-Large 和 T5-XXL 以及上训练 MQA 和 GQA-8 XXL 模型(上训练比例 α = 0.05)的所有数据集的平均性能与平均推理时间的关系。相对于 MHA 模型,更大的上训练 MQA 模型提供了有利的权衡,与 MHA-Large 相比,具有更高的质量和更快的推理速度。此外,GQA 还实现了显着的额外质量提升,实现了接近 MHA-XXL 的性能和接近 MQA 的速度。表 1 包含所有数据集的完整结果。
Ablations
本节提供实验来研究不同建模选择的效果。
-
Checkpoint conversion 图 4 比较了不同检查点转换方法的性能。均值池似乎效果最好,其次是选择单个头,然后是随机初始化。直观上,结果按照预训练模型中信息保留的程度排序。

-
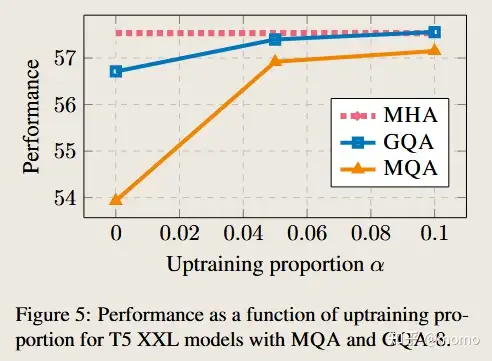
Uptraining steps 图 5 显示了使用 MQA 和 GQA 的 T5 XXL 的性能随上行训练比例的变化。首先,我们注意到 GQA 在转换后已经达到了合理的性能,而 MQA 需要上训练才是有用的。 MQA 和 GQA 都从 5% 的上调中获得收益,但从 10% 开始收益递减。
-
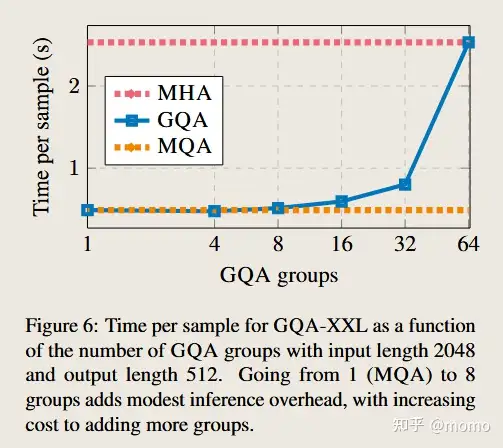
Number of groups 图 6 展示了 GQA 组的数量对推理速度的影响。对于较大的模型,KV 缓存的内存带宽开销受到的限制较小,而由于头数量的增加,键值大小的减少更加明显。因此,增加 MQA 中的组数量最初只会导致适度的放缓,随着越接近 MHA,成本也会增加。因此该实验中8组是最优选择。
Related Work
这项工作的重点是通过减少加载键和值的内存带宽开销,在解码器质量和推理时间之间实现更好的权衡。后续工作表明多查询注意力对于长输入特别有帮助
已经提出了许多其他方法来减少键和值以及参数的内存带宽开销。 Flash attention构建了注意力计算,以避免具体化二次注意力分数,减少内存并加快训练速度。量化通过降低精度来减小权重和激活(包括键和值)的大小。模型蒸馏而是在给定精度下减小模型大小,使用较大模型生成的数据来微调较小模型。层稀疏交叉注意消除了大多数交叉注意层,这些层构成了较长输入的主要费用。推测性采样通过使用较小的模型提出多个标记,然后由较大的模型并行评分,从而改善了内存带宽瓶颈。
Conclusion
语言模型的推理成本很高,主要是因为加载键和值会产生内存带宽开销。多查询注意力减少了这种开销,但代价是模型容量和质量下降。我们建议使用一小部分原始预训练计算将多头注意力模型转换为多查询模型。此外,我们引入了分组查询注意力,这是多查询和多头注意力的插值,它以与多查询注意力相当的速度实现了接近多头的质量。
Training Stability
我们发现多查询注意力可能会导致微调过程中的训练不稳定,特别是与长输入任务相结合。我们从头开始训练了多个具有多查询注意力的 T5-Large 模型。在每种情况下,预训练都会遭受频繁的损失峰值,并且在对长输入任务进行微调时,最终模型会立即出现分歧。经过训练的多查询注意力模型更加稳定,但仍然显示出较高的方差,因此对于不稳定任务的多查询模型,我们报告了三次微调运行的平均性能。然而,经过训练的分组查询注意力模型似乎是稳定的,因此我们没有进一步研究多查询不稳定的根本原因。
transformor模型可以分为编码器和解码器两部分,但是编码器和解码器的prefill阶段都是计算密集型,可以并行进行处理。而解码器的decode阶段是内存密集型,必须一个token一个token的进行处理,最终生成输出序列。因此decode阶段的kvcache压力比较大。
因此llm推理优化的核心要点可能是一下两部分:
- prefill阶段优化计算和通信
- decode阶段优化kvcache的内存访问
评论