记录最近阅读的30篇论文
[toc]
Attention Is All You Need
大模型的奠基之作,介绍了Scaled Dot-Product Attention,attention以及transformer架构,

在 Attention is All You Need这篇论文中,作者首次提出了基于 Attention 的 Transformer 架构,并在 机器翻译(Machine Translation) 任务上进行了实验,显著提升了性能。该工作被认为是 大语言模型(LLM)时代的起点,因为其提出的自注意力机制(Self-Attention)有效解决了 RNN/CNN 在长序列建模中的诸多不足。
在计算注意力分数时,自注意力机制需要对序列中 每一个 token 与序列中所有其他 token 之间的关联进行计算,即计算 Query 和 Key 的点积:$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^{T}}{\sqrt{d_k}}\right)V$
其中矩阵 $QK^T$ 的形状为 $N \times N$,意味着:
- 对于长度为 $N$ 的序列,需要计算 $N^2$ 次 token 对之间的相似度
- 因此 Attention 的计算复杂度为 $O(N^2)$,随序列长度增长呈 平方级增长
- 无论两个 token 在序列上相距多远,它们之间都需要计算 attention 分数
这种全连接的注意力结构带来了强大的全局上下文建模能力,但代价是:
- 计算量与存储量巨大(需要存储 $N^2$ attention matrix)
- 当序列长度从 2k → 16k 时,计算和显存开销急剧增长
- 限制了长上下文场景(如长文档理解、多轮对话、代码建模)的发展
因此,Transformer 的 attention 机制虽然拥有强大的全局建模能力,但其计算与显存开销随序列长度呈平方级增长,是长上下文场景中的主要瓶颈。这一限制直接推动了 FlashAttention 等高效注意力优化算法的诞生,也为 LLM 时代的系统优化研究奠定了基础。
Fast Transformer Decoding: One Write-Head is All You Need
传统的多头注意力(MHA)为每个注意力头分别维护一组 Key 和 Value,因此在推理阶段需要缓存所有头的 KV,这会带来巨大的显存开销,尤其是长序列场景下 KV Cache 会随着序列长度线性增长。MQA 的核心思想是所有的 Query 依然保持多头,但所有 Query 共享同一组 Key 和 Value。这样的设计显著减少了推理阶段的 KV 缓存大小,从而提高推理速度并减少显存消耗。
因为减少 Key 和 Value 的数量会降低注意力机制的表达能力,因此能否在不显著损失精度的前提下加速推理是研究的重要点。论文作者采用 uptraining 的方式,将已经训练好的 Transformer 模型用 MQA 结构继续训练,使其适应改变后的注意力结构。实验结果表明,模型在推理速度上有显著提升,而模型精度仅有非常轻微的下降,甚至在部分任务上几乎无损。
这些结果说明,多头注意力中存在大量冗余结构,尤其在 Key 和 Value 的维度上存在重复信息。在保证模型性能的前提下,可以减少这些冗余,从而提升推理效率。因此,在实际运行时并不需要完整保留所有 KV heads,这为后续高效注意力结构提供了基础。
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints

这篇论文提出了 GQA(Grouped Query Attention),它是介于传统的多头注意力(MHA)和多查询注意力(MQA)之间的一种折衷设计。在 GQA 中,将多个 Query 头划分成若干组,每一组内的 Query 共享同一份 Key 和 Value,而不是像 MHA 那样每个 head 独立,也不是像 MQA 那样所有 head 全部共享同一个 KV。对于组内的处理,可通过对原来各个 head 的 Key 和 Value 进行平均或线性合成来生成该组共享的键和值。
因此,GQA 的两个极端情况分别对应:当组数等于 head 数时,退化为 MHA;当组数为 1 时,退化为 MQA。因此 GQA 可以被视为 MHA 和 MQA 之间的连续可调结构压缩方案。
GQA 的提出主要解决了 MQA 在表达能力上的潜在损失问题。虽然 MQA 可以显著减少推理阶段 KV Cache 的显存占用,从而加速模型推理,但过度共享 KV 会导致多头注意力之间的表达差异被抹平,从而可能带来精度下降。GQA 通过限制共享的粒度,使模型在降低 KV Cache 开销的同时,仍保留一定程度的 head 多样性,从而在推理效率和模型精度之间取得更好的平衡。
实验表明,GQA 在精度损失上通常比 MQA 更小,同时仍能获得显著的推理加速,特别适合大模型推理场景。在真实部署中,GQA 能够减少 KV Cache 大小,提高 GPU 利用率,使得更大的 batch、更长的上下文、更高的并发部署成为可能。因此,GQA 是现代大语言模型(例如 LLaMA、Qwen 等)普遍采用的注意力结构,对高性能推理至关重要。
总结而言,GQA 证明了注意力头之间存在大量冗余,并展示了减少冗余维度仍可以保持模型表达能力的可能性
DHA: Learning Decoupled-Head Attention from Transformer Checkpoints via Adaptive Heads Fusion

这篇论文提出了DHA(Decoupled-Head Attention,解耦头注意力)机制,主要解决大语言模型推理时的计算和内存开销问题。
论文设计了一种解耦头注意力机制,能够在不同层自适应地为键头和值头配置组共享,在性能和效率之间实现更好的平衡。
论文的创新点在于自适应头融合(Adaptive Heads Fusion):
- 通过三个阶段将传统多头注意力(MHA)快速转换为DHA:搜索、融合和持续预训练
- 首先对相似功能的注意力头进行聚类分组
- 然后通过线性融合相似头的参数,保留原始模型的知识
- 不同层根据其冗余程度分配不同数量的键头和值头
实验显示DHA只需要原始模型0.25%的预训练预算就能达到97.6%的性能,同时节省75%的KV缓存 。与Group-Query Attention(GQA)相比,DHA实现了5倍的训练加速和更好的性能。
简单来说,这篇论文提供了一种高效的方法,能够将已有的Transformer模型转换成更节省计算和内存的版本,且只需极少的额外训练成本。
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning

Flash Attention系列论文提出了一种创新的注意力机制优化方法,通过分块(tiling)计算策略显著加速了Transformer模型中attention的计算过程。这一方法的核心思想是充分利用GPU的内存层次结构,通过精心设计的分块策略来减少高带宽内存(HBM)的访问次数。
Flash Attention的基本原理:
传统的attention计算需要将完整的Q、K、V矩阵加载到GPU内存中,计算QK^T后再进行softmax归一化,最后与V相乘得到输出。这个过程涉及大量的内存读写操作,成为计算瓶颈。Flash Attention通过将Q、K、V矩阵分割成更小的块,每次只将一小块数据加载到GPU的片上内存(SRAM)中进行计算,从而大幅减少了对慢速HBM的访问。
Flash Attention 2的优化策略:
在Flash Attention 2中,计算流程采用了更优化的循环嵌套结构:外层循环遍历Q矩阵的分块,内层循环遍历K和V矩阵的分块。这种组织方式相比第一代进行了调整,能够更好地利用GPU的并行计算能力,减少同步开销,并提高计算单元的利用率。具体来说,对于每个Q块,依次处理所有的K、V块,通过累积的方式逐步计算出最终的attention输出。
Online Softmax算法:
传统的softmax计算通常需要三次遍历(3-pass):第一次计算最大值用于数值稳定性,第二次计算指数和,第三次进行归一化。这种多次遍历会产生额外的内存访问开销。Flash Attention采用了online softmax(也称为safe softmax)算法,将这个过程优化为单次遍历(1-pass)。
Online softmax的关键在于维护一个运行时的最大值和累积和,在处理每个新的分块时,动态更新这些统计量,并对之前已计算的结果进行相应的重新缩放。具体来说,当处理新的K、V块时,会计算当前块的注意力分数,更新全局最大值,然后使用新的最大值对之前的累积结果和当前结果进行修正,最后累加到输出中。这种增量式的计算方式避免了多次完整遍历,显著降低了内存带宽需求。
性能提升:
通过结合分块计算和online softmax算法,Flash Attention 2实现了以下优势:
- 降低内存访问: 将大部分中间计算保持在快速的SRAM中,减少了HBM访问次数
- 提高计算效率: 优化的循环结构提升了GPU计算单元的利用率
- 保持数值精度: 尽管采用了增量计算,仍能保证与标准attention完全相同的数值结果
- 支持长序列: 内存效率的提升使得处理更长的序列成为可能
这些优化使得Flash Attention 2相比标准实现获得了数倍的加速,并且这种加速在长序列场景下更加明显,为大规模语言模型的训练和推理提供了重要的技术支撑。
H_2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models

这篇论文主要介绍稀疏注意力计算,虽然和我现在目前的学习重合度不高,但是我还是简单看了一下,这篇论文是发现注意力计算中的部分token起到了比较大的作用,这有点类似二八定律,因此在推理中只保留这部分比较重要的token,同时驱逐不重要的token,能够保持性能的同时大幅度提高推理速度。
这项工作对长文本生成特别重要。通过只保留20-30%的KV Cache,H2O可以在几乎不损失性能的情况下,将推理速度提升数倍,并支持更长的上下文长度。这对于实际部署大语言模型非常有价值。
H2O提出了一种动态的KV Cache管理策略:
-
Heavy-Hitter识别: 通过追踪每个token的累积注意力分数,识别出那些持续获得高注意力权重的”重量级”token
-
动态驱逐策略: 当KV Cache达到预设大小时,选择性地驱逐那些注意力分数较低的token,只保留:
Heavy-hitter tokens(注意力权重大的关键token) Recent tokens(最近生成的token)
-
保留策略: 最近的token通常也很重要(局部性原理),所以即使它们当前的累积注意力分数不高,也会被保留
EFFICIENTLY SCALING TRANSFORMER INFERENCE
这篇论文介绍了如何推理一个100b到500b的模型,感觉对我目前的帮助不是很大,因此我现在主要还是学习单卡推理阶段,对于张量并行,流水并行相关的研究还不是很多。
这篇论文讲解了如何在一个多卡的集群中并行attention计算以及并行FFN计算,然后还提出了相关的符号定义比如:计算FLOPs的分析内,存访问模式,通信开销的量化,并行策略的形式化描述,这对后续的研究起到了一个基础的导向作用,因此这篇论文对于理解推理流程还是十分重要的。
同时这篇论文指出了计算和内存的瓶颈计算方法,全面介绍了推理的流程和开销的来源。
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving

这篇文章使用分离prefill阶段和decode阶段来完成推理过程,但是我认为这个技术在几年之前都已经是业内共识(经常听别人讨论),本文的主要贡献可能是使用模拟器系统分析了pd分离对比vLLM以及 DeepSpeed-MII。本文做的pd分离在多卡并行的策略上是使用了prefill和decode分离到不同的gpu上运行,做了一个类似流水线似的工具。对比不同策略他们的性能差异发现目前pd分离还是有优势存在的,本文通过实验证明了在特定的场景下,pd分离仍然具有优势存在。
vllm目前还没有使用pd分离,而是集成了chunked-prefill,这个实现更加的简单,不需要跨集群通信,在需要低延迟的场景下更加的有优势。
Efficient Memory Management for Large Language Model Serving with PagedAttention

这篇论文借鉴操作系统的分页内存的方式,来管理gpu中的显存,这样可以减少显存利用中的碎片问题(包括内部碎片,外部碎片,这个操作系统的相关概念类似)。
使用分页的方式将kvcache分成固定大小的块,每个kvcache由不同的非连续页组成,改变了以往的连续页的管理方式,此时碎片只有最后一个块中的部分,与操作系统中的概念相同。显存页可以按需申请,因此在推理时降低了对显存的需求。同时对不同页内的显存进行计数,使得不同的sequence可以共享同一个显存块(这里使用copy on write的方式共享),从而减少显存的利用。
当显存不足或者是有抢占式的sequence到来时,使用两种策略来对驱逐出去的kvcache进行重新生成,包括重计算或者保存到内存之中,论文也做了实验来比较这两种策略的差异。
Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
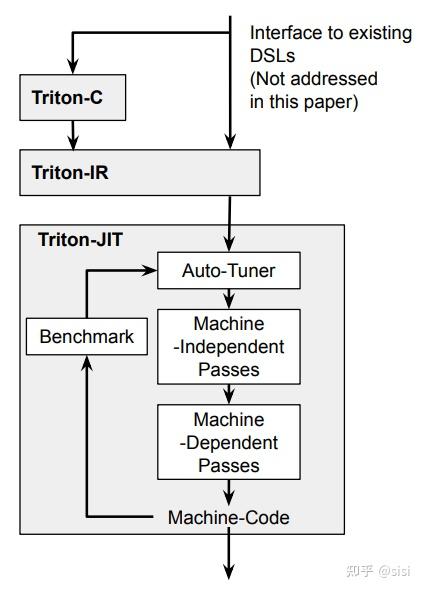
论文中提出了Triton-C,一种类C的领域特定语言。现在的Triton改用Python作为前端语言,因为Python更容易被机器学习社区接受,学习成本更低。但是论文中提出的分块计算和广播等机制和python中的概念不谋而合。
Triton的核心特性比如分块计算、程序ID、张量广播等,是Triton编译器自己实现的,而不是直接用Python或NumPy的功能。Python只是作为语法的载体,让写kernel代码更简单。编译器后端是用C++/MLIR实现的,最终生成的是GPU机器码。
从Triton-C到Python-Triton的演进,主要是为了降低使用门槛,让更多研究者和工程师能够方便地写高性能GPU代码,而不需要深入了解CUDA编程的细节。
Enabling Tensor Language Model to Assist in Generating High-Performance Tensor Programs for Deep Learning
这篇论文提出了一种利用张量语言模型(Tensor Language Model)来辅助生成高性能深度学习算子代码的方法。它核心解决的是传统深度学习编译器(如 TVM)在自动调优(Auto-tuning)时搜索空间过大、耗时过长的问题。通过训练或微调大语言模型,让其学习张量程序的结构与优化规律(如循环切分、向量化等),LLM 能够直接根据算子描述预测出高质量的优化方案,从而代替或加速原本漫长的“试错式”暴力搜索。就是用大模型作为向导,指导编译器快速生成运行最快的底层代码,既大幅缩短了编译优化时间,又提升了深度学习模型的最终推理性能。
和我目前研究方向似乎相关性不大,但是还是看了一看。
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management

InfiniGen 这篇论文的核心定位可以看作是 H2O 的无损进阶版。它延续了 H2O 关于稀疏注意力的观察,即只有少部分 Token 对推理重要,但在策略上从单纯的驱逐转变为卸载。它将全量 KV Cache 保存在容量巨大的 CPU 内存中作为后备存储,仅将当前计算预测出的重要 Token 动态加载到 GPU 显存中。相比 H2O 直接丢弃 Token 导致的长文本精度永久损失,InfiniGen 理论上拥有无限的序列长度,且因 CPU 保存了全量数据,保证了模型在长文本下的无损或近乎无损的精度。
在核心算法方面,SVD 分解并非在推理时实时进行,而是采用“离线重构,在线预测”的策略。基于 Attention 矩阵中存在承载关键信息的异常值这一观察,InfiniGen 在离线阶段利用 SVD 对模型的 WQ 和 WK 权重矩阵进行变换(即 Query/Key Skewing)。这一步旨在主动聚合特征,将分散的重要性信息集中到少数几个维度上。因此在在线推理时,无需计算完整 Attention 矩阵,仅需检查这几个特定维度的值,就能以极低的成本推测出哪些 Token 是重要的,从而实现快速筛选。
在系统设计上,为了解决 GPU 与 CPU 之间 PCIe 带宽的瓶颈,InfiniGen 设计了推测性预取与统一缓冲池机制。利用 SVD 带来的预测能力,系统在计算当前层时,会提前推测出下一层需要的 KV Block,并利用 PCIe 带宽提前将其从 CPU 预取到 GPU,从而掩盖数据传输延迟。GPU 显存被设计为一个统一缓冲池,结合引用计数和预测结果,当显存不足时,优先驱逐那些预测未来不再被引用的 Block,这使得显存管理既保持了极高的命中率,逻辑又保持了简洁。
总的来说,InfiniGen 通过 SVD 离线重构权重让关键 Token 变得可预测,配合 CPU-GPU 动态卸载与预取机制,实现了在极小 GPU 显存占用下,对超长上下文进行高效、高精度的生成。
The Deep Learning Compiler: A Comprehensive Survey
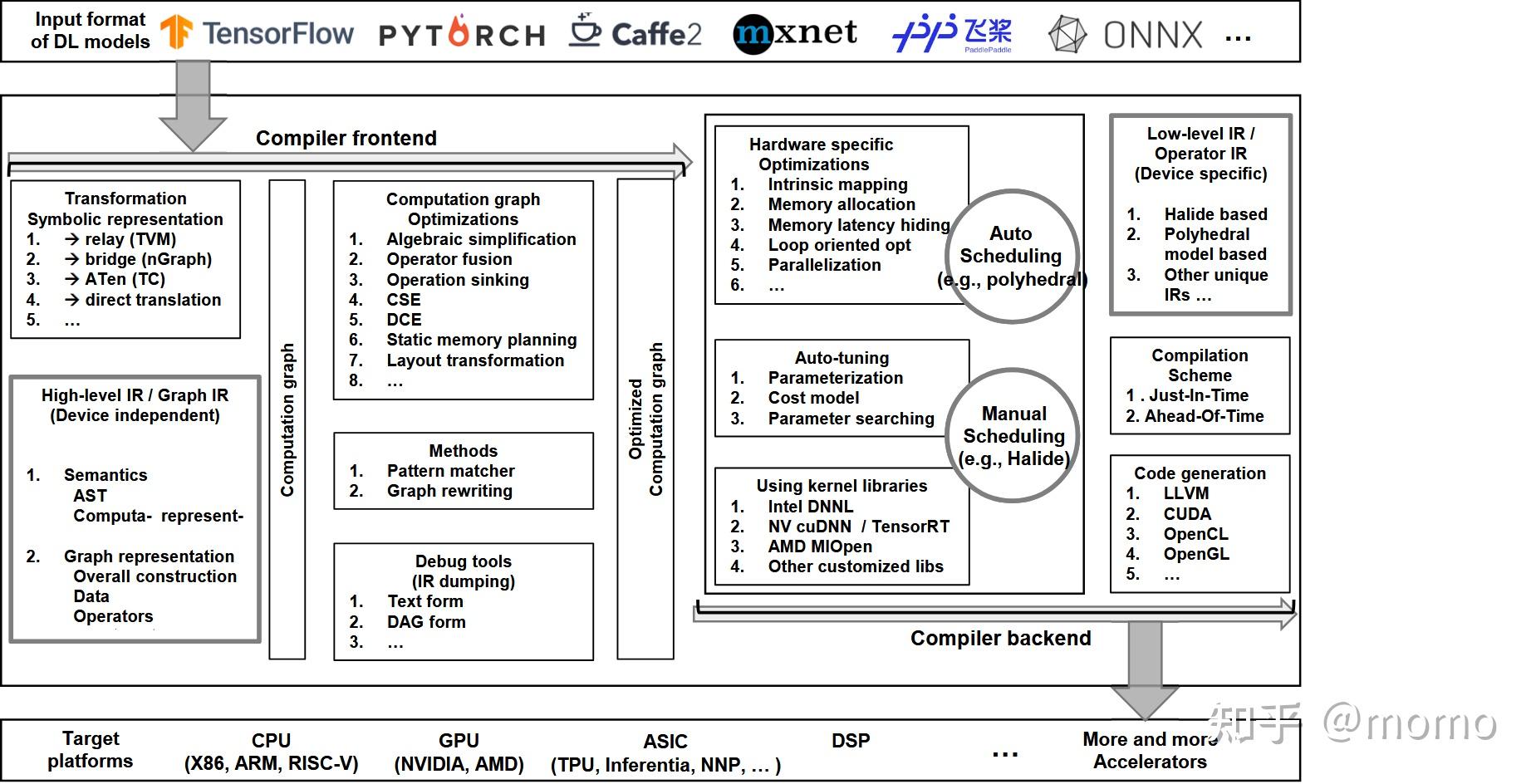
这篇《深度学习编译器:综合综述》论文确实可以被视为 AI 编译器领域的入门级教科书,因为它系统性地将深度学习模型从高层框架抽象到低层硬件执行的整个转换过程进行了详尽的剖析。它不仅仅是概念的罗列,更是将前端、后端、优化技术以及软硬件协同设计的历史脉络和关键挑战都囊括在内,为读者构建了一个完整的知识框架。
该综述首先详细介绍了编译器前端(Frontend)的工作流程,即如何将用户在 TensorFlow、PyTorch 等框架中定义的模型,转换为编译器能够理解的中间表示(Intermediate Representation, IR)。IR 是编译器的核心,常见的 IR 具有图形表示(如计算图)和代数表示(如数据流)的特点。前端的主要任务包括图的构建、抽象,以及最初级的高层图优化,比如将多个连续的小操作融合成一个更大的操作(Operator Fusion),以减少内存带宽的开销和内核启动的延迟。 这个阶段关注的是模型的逻辑结构和数据流的全局视图。
接着,论文深入探讨了编译器中端(Middle End)和核心优化技术。这是编译器发挥最大作用的地方,它负责在保持模型计算正确性的前提下,进行各种性能增强的转换。重要的优化包括内存调度和复用(Memory Scheduling and Reuse),旨在最小化内存峰值和张量传输;自动微分优化,确保训练阶段的反向传播计算高效;以及复杂的图重写(Graph Rewriting),根据启发式规则或搜索算法来找到最优的计算图结构。对于大规模模型,图划分(Graph Partitioning)也是中端的关键任务,它决定了模型的哪些部分应该被分配到 GPU、CPU 或专用加速器上执行,以实现异构硬件的最佳利用。
最后,综述重点落在编译器后端(Backend)和代码生成。后端是连接软件和硬件的桥梁,负责针对特定的目标硬件(如 NVIDIA GPU、Intel CPU、Google TPU 或定制 ASIC)生成高效的机器码。这一阶段涉及大量的低层优化,包括循环平铺(Loop Tiling)以提高数据局部性、数据排布转换(Data Layout Transformation)以适应硬件的内存访问模式,以及线程和指令调度(Thread and Instruction Scheduling)。近年来,自动调优(Auto-Tuning)技术的兴起,如 TVM 的 AutoTVM 和 Ansor,极大地提高了后端代码的优化水平,通过自动化搜索算法替代了复杂的手动优化过程。这些技术允许编译器在大量可能的低层实现中,找到针对特定模型和特定硬件的最优内核。
MLIR: Scaling Compiler Infrastructure for Domain Specific Computation
MLIR 的设计目标是建立一个能够处理各种领域特定抽象、同时又能有效进行代码生成的编译器基础设施。其核心设计原则主要有以下四个方面:
Dialect(方言)与可扩展性 是 MLIR 最核心的抽象机制,是实现其高可扩展性的基石。每个 Dialect 都定义了一组特定的操作、类型和属性,用于建模特定层次的抽象或特定计算领域。例如,存在高级方言(如表示 TensorFlow 图的 tf 方言)、中级计算方言(如表示线性代数的 Linalg 方言)和低级硬件方言(如表示 LLVM IR 的 LLVM 方言)。通过将复杂的编译器系统分解为可插拔、可组合的 Dialect,MLIR 避免了在一个巨大的、单体的 IR 中建模所有内容,极大地提高了系统的模块化和可扩展性。
结构化、基于区域(Region)的 SSA 形式 也是 MLIR 的一个关键特征。它采用静态单赋值(SSA)形式,并将其扩展为支持 Regions。Regions 允许将具有复杂控制流的结构(例如 while 循环、if/else 条件分支)作为 IR 中的一等公民,以结构化的方式建模。这种结构化 IR 能够长时间保留高级语义,使得优化器能够跨越复杂控制流边界进行更有效的全局分析和转换。
渐进式降级(Gradual Lowering)与模块化 意味着 MLIR 鼓励编译器设计者使用多层抽象和渐进式降级的编译策略。编译过程被分解为一系列模块化的 Pass,每个 Pass 将高层 Dialect 的操作逐步转换为较低层 Dialect 的操作。例如,从 tf 方言降级到 Linalg 方言,再降级到 LLVM 方言。这种策略使得编译器逻辑更清晰、更容易维护和调试,因为每个转换都只关注特定层次的优化。
共享的基础设施(Shared Infrastructure) 是实现效率的关键。尽管 MLIR 支持大量的 Dialect,但它提供了一套统一且共享的基础设施,包括分析工具、通用 Pass、序列化和诊断报告。所有 Dialect 都能复用这些核心组件,这避免了为每个新的领域或硬件目标重复构建编译器的基础结构,从而极大地提高了开发效率。
目前完成15篇论文,贷款15篇
2025年12月6日
评论